Тестирование в production — 2
(Из ленты Чудес не бывает или я ошибаюсь?)
Development → Staging → Production pic.twitter.com/xIohpoaWqw— Daniel Stefanovic (@DaniStefanovic) March 29, 2018
Testing in Production, the safe way (by Cindy Sridharan @copyconstruct)
Topics include:
— why test in prod when you can test in staging
— how to test in prod while minimizing risk
— how to test configuration changes in prod
— why proxies are your best friend
— what to monitor
— and more
Опыт использования Gremlin (Chaos Engineering tool) в Remind (ссылка)
“Chaos Engineering allows us to have ‘pre-mortems’ instead of post-mortems.”
— Michael Barrett, Head of Infrastructure Engineering, Remind https://t.co/F4uVpTiWDa— Philip Gebhardt (@PhilGebhardt) April 4, 2018
Интересный коммент про вышеуказанную статью: «»instead» would be nice, but that’s not how it works in reality. Chaos Engineering is not a substitute for postmortems. We still need to learn from actual incidents because systems will continue to fail (probably less frequently though)»
Diffy tool от Twitter для проверки новой версии путем сравнения результатов ее работы с текущей.
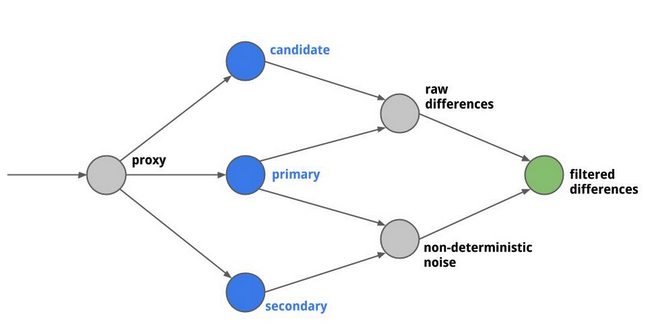
Тесты в проде — это не «ХХ и в прод», это все требует понимания monitoring и observability:
 |
| Observability |
«Don’t attempt to «monitor everything». You can’t. Engineers often waste so much time doing this that they lose track of the critical path, and their important alerts drown in fluff and cruft» — Observability and Understanding the Operational Ramifications of a System
“Tips for High Availability” by Netflix Technology Blog
Engineering Large Systems When You’re Not Google Or Facebook (test in prod) (by Charity Majors @mipsytipsy)
«Fuck staging, test in production» @mipsytipsy
— Scott Pringle (@Luciam91) April 27, 2018