Интеграция информационных систем. Борьба с неконсистентными данными.
(Из ленты Курсы бизнес анализа, тренинги и обучение бизнес аналитике| ArtofBA)
Коллеги, привет! Меня зовут Бравин Илья, и сегодня я хочу поделиться с вами своим опытом использования Open Source решения Apache Zeppelin для упрощения и ускорения процесса выявления неконсистентных данных в интегрированных системах с различными базами данных.
Также расскажу, как мы выстроили процесс работы с неконсистентными данными.
О чем будет статья
- Кратко о себе и компании, в которой работаю.
- О неконсистентных данных в энтерпрайз системах простым языком.
- 4 причины появления неконсистентных данных.
- Первый случай выявления неконсистентности.
- Как мы находили неконсистентность, что нас не устраивало и к чему пришли.
- Вы узнаете, почему мы выбрали именно Apache Zeppelin как решение для частичной автоматизации процесса поиска неконсистентности.
- Покажу реальный пример работы с Apache Zeppelin.
- Расскажу про кейсы, когда данный инструмент может быть полезен вам.
- Дам список ссылок на полезную литературу по работе и установке Apache Zeppelin.
Кому будет полезен материал?
В первую очередь бизнес-аналитикам и системным аналитикам из IT-индустрии, работающими с Энтерпрайз системами в разрезе данных там, где присутствует одно или сразу оба условия одновременно:
а) Все системы/модули/сервисы интегрированы между собой через синхронизацию данных
б) Данные в системах хранятся в различных БД (например, MySQL и PostgreSQL или Oracle Database, Elasticsearch)
Вводная часть
Для начала, хотел бы немного рассказать о себе и о компании. На данный момент у меня более 6 лет опыта аналитической и консалтинговой работы.
На прошлом месте я в составе консалтинговой команды в течение четырех лет внедрял систему управления активами предприятия от IBM на 10 теплоэлектростанциях в различных регионах России, а на данный момент я на протяжении 2,5 лет являюсь системным аналитиком в логистической компании СДЭК в блоке CRM (отвечаю за модули Контрагент, Договор, Отчет менеджера продаж во внутренней ERP).
Я, как и многие коллеги, работающие в компаниях, существующих более 10 лет, помогаю переводить функциональность и данные из старой монолитной системы в новую микросервисную.
Для понимания масштабов компании приведу несколько метрик:
- 300 тыс. заказов в день
- 15 млн контрагентов
- 750 тыс. Договоров
- 25 тыс. сотрудников
- 3000 ПВЗ в 20 странах
- Отдел IT — 350 человек
В дальнейшем для термина «неконсистентные данные» я буду применять сокращение — «НКД».
Проблематика
Как показывает опыт общения с коллегами, во многих проектах данные могут стекаться из разных источников, храниться в разных базах, кто-то может пользоваться дополнительно сторонними сервисами аналитики. Соответственно, перед аналитиками порой встают задачи “подружить” такой зверинец между собой.
В данной статье мы рассмотрим ситуацию, когда причиной, по которой необходимо “подружить” зоопарк систем в разрезе данных, является выявленная или пока потенциальная НКД между связанными системами.
Для наглядности, представьте, что у вас есть две системы “А” (монолит) и “Б” (микросервисы).
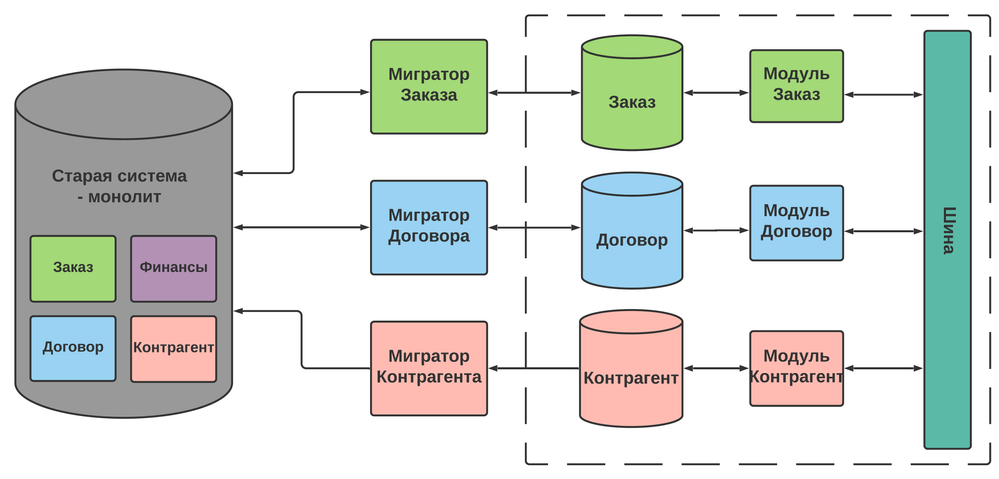
Большая часть пользователей работает в новой системе, а меньшая — в старой. Часть работает и там, и там.
Часть модулей имеют уже только одностороннюю миграцию ( из новой системы в старую), но большая часть — двустороннюю.
В новой системе отсутствует часть модулей, которые есть в старой ( например, Финансы) — они в процессе “переезда”.
Неконсистентные данные
Консистентность данных — согласованность данных друг с другом, целостность данных.
Если сказать простыми словами, то неконсистентность в данных — это различие в данных между системами в разрезе конкретного объекта или атрибута.
Как вы думаете, чем вообще грозит неконсистентность между двумя и более связанными Энтерпрайз системами?
Представьте, что у вас 50 тыс. договоров в старой системе имеют верный номер договора, а в новой системе — отличающийся.
Тогда все взаиморасчеты с клиентами по данным договорам могут “встать”, когда другие модули, которым для работы нужен номер Договора, начнут брать данные из новой системы. Причем с учетом массовости проблемы, это может просто остановить бизнес в целом на какое-то время!
Или, например, адреса доставки возвратов разные для 1% заказов (что для нас около 3 тыс. заказов) или телефон у клиента разный в разных системах, а на него приходят все уведомления и смс — насколько велики будут потери в деньгах и репутации?
4 причины возникновения НКД
Проработав более 6 месяцев по задачам связанным с НКД, мы выявили следующие причины их возникновения:
1. Ошибки в маппинге между моделями данных в любом из направлений миграции
Пример: статусы или любые другие списочные данные конвертируются неверно при миграции сущностей из одной БД в другую ( особенно, если статусные модели разные или списки давно не актуализировались в одной из систем).
2. Различаются обязательные атрибуты между системами (из-за этого сущности могут зависать в миграторе, не переходя в другую систему).
Пример: в старой системе есть необязательное поле “Адрес”, а в новой оно обязательное. Тогда миграция сущности, у которой оно не заполнено, из старой в новую систему не произойдет, а зависнет с ошибкой. Потенциально это может привести к НКД уже в разрезе сущностей, а не атрибутов.
3. Отсутствует событие на миграцию в другую систему (потерялось или вообще не создавалось)
Пример: событие на миграцию из старой системы в новую создавалось только при стандартном сохранении объекта через пользовательский интерфейс.
Т.е. изначально не заложили, что при изменении какого-то атрибута объекта не через пользовательский интерфейс (например, триггер или техподдержка делает запись напрямую в БД) создавалось событие на миграцию в новую систему.
4. Массовые ручные обновления боевых данных в БД
Пример: такие обновления часто нужно выполнять сразу во всех связанных системах, что при ручном исполнении приводит к постепенному росту неконсистентности данных из-за человеческого фактора.
Рекомендация: если вы выявили неконсистентность данных у себя в проекте, пройдите по этому чек-листу. Велика вероятность, что ваша причина здесь уже есть!
Первый случай с НКД
Однажды я разбирал уже третий однотипный тикет в jira от пользователей, которые жаловались, что в существующем долгое время договоре «слетели данные» по подразделению в новой системе.
Первое, с чего я начал — убедился, что в старой системе данные верные. Тогда я решил сравнить значения этого поля по всем договорам между двумя системами.
Итак, что у нас было перед началом выгрузок:
а) Две разные системы “А” и “Б” с различными БД (MySQL и PostgreSQL).
б) Модуль “Договор” существует и в старой системе, и в новой, люди работают и там, и там, миграция данных двусторонняя синхронная.
в) Договоров — 500 тыс.
г) Сервера стоят в Новосибирске — мы в СПБ.
Что пришлось делать:
а) разработчик делал выгрузку из 2-х БД в локальный PostgreSQL
б) разработчик конвертировал модели и сопоставлял данные из двух систем в разрезе Договора
в) я работал с выборкой данных (искал паттерны)
г) я согласовывал решение проблемы с бизнесом
д) разработчик повторял выгрузки с учетом новых вводных от бизнеса
Из-за того, что у нас разные типы бд, сделать запрос в одном окне программы для запросов в БД (например, в DataGrip) не представлялось возможным.
Поэтому разработчику пришлось выгружать две выборки по 500 тыс. договоров из двух баз. Только выгрузка заняла в сумме около 4 часов!
После этого разработчик конвертировал и сопоставлял данные из двух выборок в локальном DataGrip, что заняло еще более 30 мин.
И только после этого к работе приступал я. По сути, первично, меня интересовал масштаб проблемы, так как в зависимости от него и способы решения были различные.
Наш выгрузка показала около 1 тыс. договоров с разными Подразделениями. Явного тренда или зависимости я не обнаружил, поэтому быстрого решения тут не было, требовалось привлекать бизнес.
Когда бизнес увидел выборку, ему было нужно несколько дополнительных атрибутов в ней, чтобы разобраться, а в какой же из систем верные данные, что потребовало повторения процедуры выгрузки.
Резюме: у нас ушло более 8 часов времени разработчика и аналитика на то, чтобы предоставить бизнесу такую выборку, которая сможет дать ему необходимые данные для принятия решения.
Требования к инструменту
После нескольких таких выборок, мы решили найти инструмент, который позволит ускорить нахождение НКД для систем с различными БД, а также позволит привлекать разработчиков только при особо сложных случаях.
Наши требования были следующими:
а) Инструмент хотелось бесплатный, так как не было понятно, насколько он нам реально нужен (может все закончится на 10 выборках), поэтому искали в open source.
б) Инструмент должен позволять один раз настроив подсоединение к различным БД, более не повторять настройки. Также он должен упростить и автоматизировать конвертацию и сопоставление данных из различных БД.
в) С учетом предварительной настройки разработчиком инструмент должен обладать возможностью работы с SQL (для автономной работы аналитика)
г) Инструмент должен обладать интуитивно понятным интерфейсом, а также возможностью визуализации данных для того, чтобы можно было безболезненно привлекать бизнес к решению.
Apache Zeppelin
Просмотрев несколько вариантов решений, остановились на двух Zeppelin и Jupiter notebook:

Нашу задачу можно было решить и с Jupiter Notebook, но потребовалось бы больше прослоек и дополнительных настроек, а также времени, так как из коробки там работа основана на Python или языке R, а нам нужен был SQL.
Почему выбрали Apache Zeppelin
В итоге оказалось, что Apache Zeppelin удовлетворяет всем нашим требованиям, описанным выше.
Различные источники данных
Zeppelin из коробки, через Apache Spark, позволяет работать с различными источниками данных (MySQL, PostgreSQL, Cassandra, Elasticsearch, Python и пр. ).

Визуализация данных
Все стандартные виды визуализации данных присутствуют, но особых изысков нет)
Для нашей цели, как оказалось, не нужна даже такая визуализация, так как она практически не помогает бизнесу в принятии решения. Проще и быстрее при необходимости использовать стандартные возможности Excel.
Работа с SQL из коробки
За счет Apache Spark из коробки работает сервис Spark SQl, позволяющий работать с запросами в интерфейсе всем, кто может их писать.
Примеры реальной работы с Zeppelin
Ноутбуки и параграфы
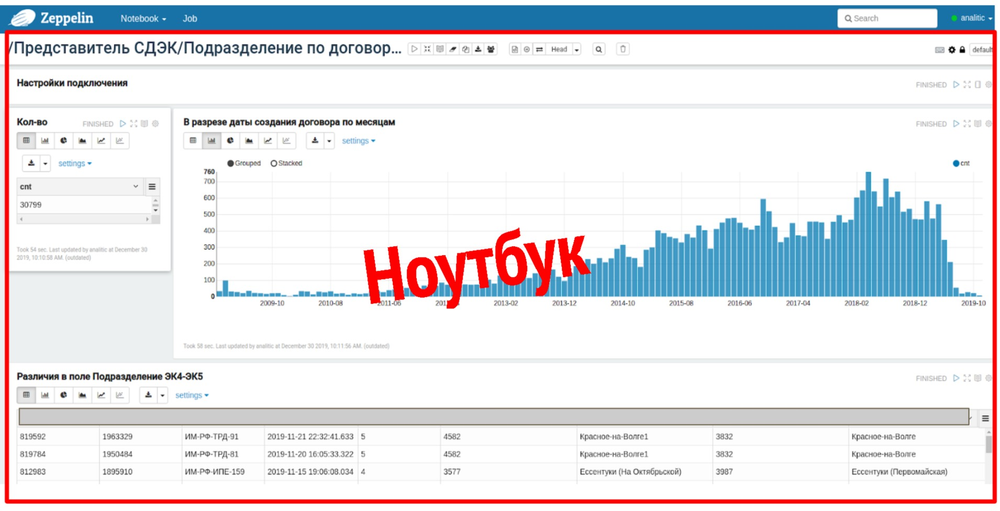
Ноутбук в Zeppelin — это аналог страницы с набором данных по отдельному бизнесовому запросу. На скриншоте вы можете увидеть ноутбук по атриубу “Подразделение» в сущности «Договор».
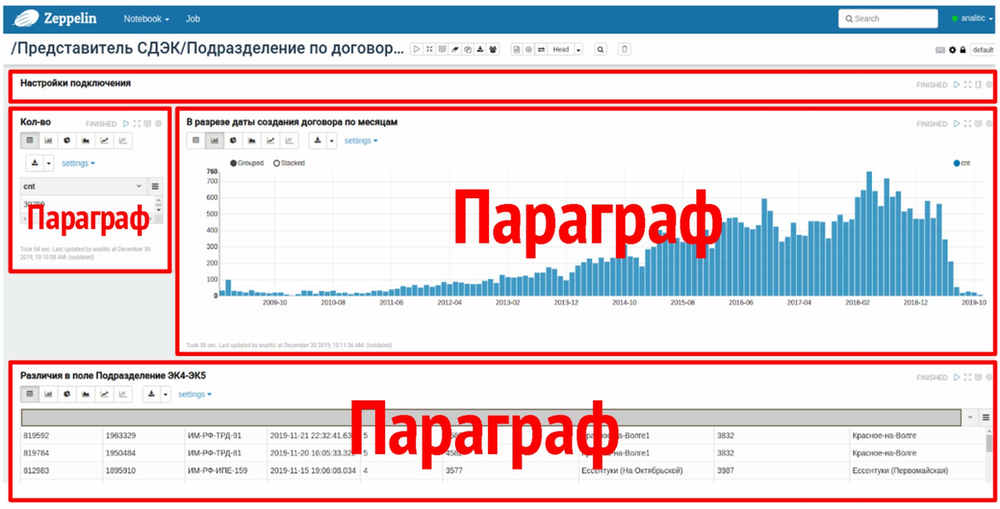
Каждый ноутбук состоит из нескольких параграфов (окон).
В большинстве случаев стандартный ноутбук состоит из следующих параграфов:
а) Настройки подключения (здесь необходимо прописывать базовые настройки для подключения к бд и базовые запросы к ним) — рассмотрим его чуть позже
б) Выгрузка по кол-ву НКД между системами (нас всегда интересует масштаб проблемы!)
в) По необходимости, визуализация распределения НКД по времени или другому разрезу
г) Результирующая выгрузка по данным для анализа (здесь нужно выводить все сопутствующие данные по проблемным сущностям — чтобы бизнес мог прямо или косвенно понять, в какой из систем данные верные)
Каждый параграф (кроме настроек подключения) состоит из двух разделов: code section, в который помещается исходный SQL запрос, и result section, где можно увидеть результат выполнения запроса. Code section для удобства скрывается автоматически.
Также у вас есть возможность запускать каждый из параграфов в отдельности (чтобы сэкономить время) или запустить сразу все параграфы внутри одного ноутбука одной кнопкой.
В целом, вы можете проводить стандартные действия с каждым из параграфов:
- скопировать существующий (чаще всего копируем «настройки подключения»)
- удалить существующий
- изменить местоположение параграфа на экране
- Изменить размер параграфа (высота и ширина)
- Изменить наименование параграфа
Теперь кратко представлю алгоритм работы аналитика по получению выгрузки по НКД:
1. Настроить подключение ко всем необходимым источникам данных.
2. Составить SQL запрос для выгрузки исходного дата сета для каждого источника данных.
3. Дать наименование каждой временной таблице, куда будет сохраняться датасет каждого источника данных.
4. Добавить новый параграф и в нем написать SQL запрос, который сравнивает полученные датасеты из временных таблиц в разрезе равенства необходимого атрибута.
5. Запустить параграф из п.4.
Далее более подробно обсудим каждый шаг.
Параграф “Настройки подключения”
Сначала идет SQL запрос на выборку данных из новой базы ( «Договор» в PostreSQL).
Этот запрос может формировать аналитик. Обычно это запрос с минимальными фильтрами. Но в нем должны выводится все необходимые косвенные данные.
val pgQuery = """(
SELECT c.name AS client_name,
cc.number AS contract_number,
\\Код подразделения
cc.subdivision_id AS subdivision_id,
\\Название подразделения
s.subdivision_name AS sub_name,
cc.status_code AS contract_status,
cc.creation_date AS contract_creation_date
FROM cl_contracts cc
JOIN clients c ON c.code = cc.cl_code
JOIN subdivision s ON cc.subdivision_id=s.code
WHERE cc.type_id = '3' \\Тип договора
) t"""Далее настройка для подключения к этой базе («Договор» в PostreSQL).
val pgDf = sqlContext.read.format("jdbc")
.option("driver", "org.postgresql.Driver")
.option("url",sc.getConf.get("test.url"))
.option("user",sc.getConf.get("test.user"))
.option("password", sc.getConf.get("test.pass"))
.option("dbtable", pgQuery)
.option("autoReconnect", "true")
.option("allowMultiQueries", "true")
pgDf.registerTempTable("new_contracts")Далее идет SQL запрос на выборку данных из старой базы ( «Договор» в MYSQL).
val pgQuery = """(
SELECT cl.name AS client_name,
c.number AS contract_number,
\\Код подразделения
c.ID_podrazdelenie AS ID_podrazdelenie,
\\Название подразделения
p.name AS pd_name,
c.status_code AS contract_status,
c.creation_date AS contract_creation_date
FROM contracts c
JOIN clients cl ON c.code = cc.cl_code
JOIN podrazdelenie p ON c.ID_podrazdelenie=p.code WHERE cc.type_id = '3' \\Тип договора
) t"""Далее настройка для подключения к этой базе («Договор» в MYSQL).
val pgDf = sqlContext.read.format("jdbc")
.option("driver", "org.postgresql.Driver2")
.option("url",sc.getConf.get("test2.url"))
.option("user",sc.getConf.get("test2.user"))
.option("password", sc.getConf.get("test2.pass"))
.option("dbtable", pgQuery)
.option("autoReconnect", "true")
.option("allowMultiQueries", "true")
pgDf.registerTempTable("old_contracts")Настройки подключения к БД (url, драйвер, логин, пароль) заполняются один раз для каждого источника данных — с этим могут помочь администраторы/разработчики.
После того как вы прописали первичный SQL и настройки подключение к БД необходимо назвать временную таблицу, которая будет хранить результаты выборки.
В последующем финальном запросе необходимо будет использовать именно это новое наименование таблицы!
Далее для каждого источника данных требуется повторить процедуру.
Количество источников данных не ограничено (в своей практике мы не использовали более 6).
Сравнение датасетов и результат
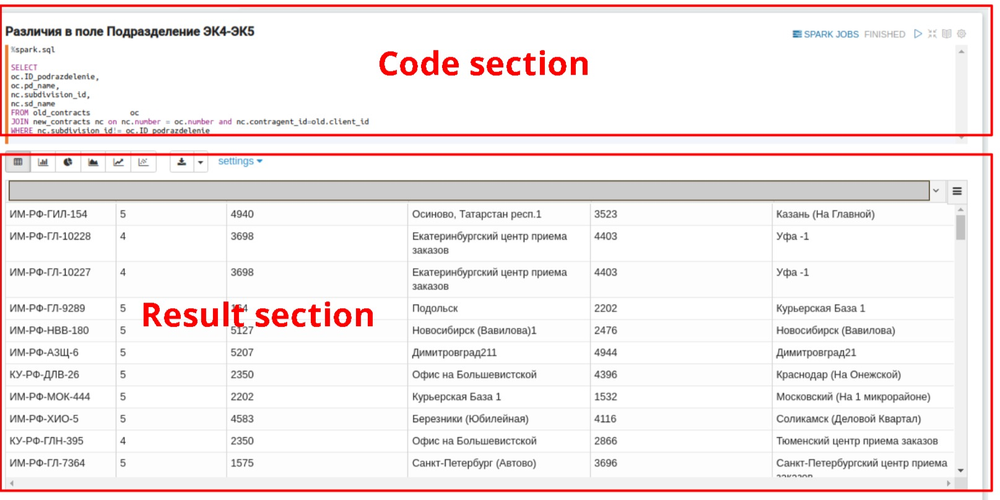
Как я говорил ранее, параграф состоит из двух разделов: code section, в который помещается исходный SQL запрос, и result section, где можно увидеть результат выполнения запроса.
Ранее в параграфе “Настройки подключения” мы инициировали создание двух временных таблиц с данными из разных БД.
Теперь нам необходимо составить условие для проверки на консистентность конкретного атрибута в разрезе сущности Договора из разных БД.
В сode section — запрос, который сравнивает два датасета из разных БД и должен выдать все договоры, у которых поле “Подразделение” отличается между датасетами.
SELECT oc.ID_podrazdelenie,
oc.pd_name,
nc.subdivision_id,
nc.sub_name
FROM old_contracts oc
JOIN new_contracts nc on nc.number = oc.number and nc.contragent_id=old.client_id
WHERE nc.subdivision_id!= oc.ID_podrazdelenieФинальная выгрузка
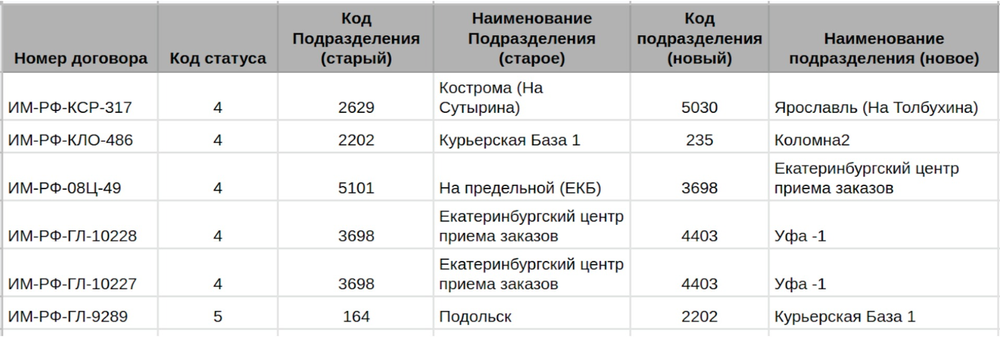
После выполнения параграфа с финальной выгрузкой и начинается аналитика данных (поиск паттернов и гипотез).
Масштаб проблемы удобнее оценивать по отдельному параграфу с численным отображением найденных сущностей с НКД.
Можно скачать файл в CSV или в TSV (рекомендую, когда у вас в выборке много данных со знаками препинания).
С этой таблицей при необходимости может работать бизнес по прямой ссылке.
Если повезло, и все данные по выборке верные в одной из систем, то ссылка на этот ноутбук копируется в jira, когда аналитик ставит задачу на проведение апдейта в БД.
Ролевая политика и совместная работа в команде
Нам удалось легко настроить разделение возможностей у пользователей, выдав им соответствующие роли, например:
а) Бизнес — могут только просматривать
б) Аналитики — могут просматривать «ноутбуки» и запускать их
в) Разработчики — могут создавать «ноутбуки» и перезагружать сервис
г) Администраторы — могут все
Мы используем 3 общие роли — нам достаточно. Можно работать совместно (но желательно не над одним проектом, это некомфортно).
LDAP и Active Directory
Zeppelin через Appach Shiro поддерживает эти распространенные способы аутентификации пользователей, так что при необходимости вы сможете быстро их настроить и упростить жизнь своим пользователям, не заставляя их придумывать новые логины и пароли.
Результаты после полугода работы с инструментом
а) кратно уменьшился срок поиска НКД
б) появилась возможность визуализировать и делиться результатом
в) сильно увеличилась автономность работы аналитика
г) появилась возможность повторить выборку нажатием кнопки «Run all»
Также сформировался новый алгоритм работы аналитика по работе с НКД:
а) Формулировка бизнес-задачи
б) Формирование SQL запросов в 2 БД для получения базовых датасетов
в) Клонирование и актуализация существующего ноутбука
г) Актуализация условий сравнения датасетов из разных БД и нужных столбцов в выборке
д) Получение данных
е) Аналитика
ж) Согласование и верификация решения с бизнесом
з) Создание задачи на апдейт в Jira со ссылкой на ноутбук в Zeppelin
*Разработчики привлекаются только для составления сложных запросов ( в 10-15% случаев)
При выявлении НКД мы запускаем (часто параллельно) два процесса — устранение последствий (определение в какой из систем данные верные, апдейт данных в другой системе), поиск и исправление причин, чтобы неконсистентные данные больше не появлялись.
Что делать в первую очередь, зависит от потенциальных последствий, которые требуется обсуждать с Product Owner и PM.
Требуется оценить, что принесет больше проблем/убытков — продолжать создавать новую неконсистентность, начав с исправления НКД (однако после исправления причины, придется править данные еще раз) или сначала найти и исправить причину НКД, а только после этого исправить НКД?
Очень часто по выявленным случаям НКД необходимо отрабатывать вручную с разработчиком, раскапывая старый код, логику миграторов или маппинга моделей.(см. чек-лист причин НКД выше). В большинстве случаев это занимает продолжительное время (от 4-6 часов и до недели, в зависимости от того, нужно ли лезть в логику монолита)
У вас может возникнуть следующий вопрос: “Зачем так много лишних действий?” — как только выявили НКД и определили, где данные верные — просто копируете полностью все данные из одной системы в разрезе атрибута в другую!
И это действительно может сработать, но только при выполнении одного условия:
вы уверены, что данные портились всегда только в одной из систем?
В нашей практике в 85% случаев, данные оказывались верными в старой системе, но пожертвовать 15% это очень ответственное решение, у которого много негативных последствий, с учетом высокой связности модулей.
Кейсы, когда Apache Zeppelin может быть полезен
Самое главное — Apache Zeppelin помогает только в поиске НКД. Он не решает причин возникновения неконсистентности!
Рекомендуем использовать Apache Zeppelin:
а) при внедрении нового/переносе существующего крупного
функционала или большого массива данных в одной из связанных систем, если у систем используются различные БД
Выделив несколько ключевых полей, вы сможете отслеживать практически в режиме реального времени, что данные мигрируют во все системы корректно.
Для этого потребуется произвести дополнительные настройки и например, подключить алерты, при появлении НКД.
Такой подход позволит минимизировать риски того, что проблема вскроется, когда уже станет критической. Глазами, вы не сможете отслеживать неконсистентность сотен тысяч атрибутов единовременно.
б) если вы никогда не проверяли системы с различными БД на НКД
Наш опыт показывает, что в таких случаях неконсистентность также может быть. У нас, например, проблема не успела “выстрелить” из-за того, что другие модули в новой системе, которые получают информацию от “Договора”, еще не вышли на prod. и не успели получить некорректные данные.
в) При необходимости сравнения выборок данных из разных БД
Это просто удобный инструмент для такого типа задач ( у нас часто им пользуются разработчики).
Заключение
А вы проверяете свои системы на НКД?! Если у вас есть опыт настройки других инструментов для выявления НКД — прошу поделиться опытом в комментариях.
Ссылки на полезные материалы
Здесь подобраны ссылки на полезные материалы как для разработчиков, так и для аналитиков, чтобы развернуть Apache Zeppelin у себя и начать им пользоваться.
Apache Zeppelin — главный сайт
Допинг для аналитики: почему стоит обратить внимание на Apache Zeppelin
Руководство по работе с Apache Zeppelin
Расписание тренингов от Art of Business Analysis
Новости и статьи по бизнес-анализу — https://t.me/artofba
Источник: Интеграция информационных систем. Борьба с неконсистентными данными.